What happened at Bazelcon 2020
Last week the annual Bazelcon conference took place remotely. In this post I’ll try to summarize the talks that I found more interesting.
Keynote - State of Bazel and Announcements
The first one to take the stage was Jeff Cox, the engineering director at Google, to talk about the state of Bazel.
He remembered the history of Bazel and the idea behind the tool. During the talk, he presented the major achievements of the year. In particular, the port of Bazel for arm64 platforms, the improvement of tools like Startlark CPU profiler and remote execution profiling. On the other side, there were some lows, and Cox underlined how the huge backlog of PRs and issues that need to be addressed will be a priority for the team next year.
 Jeff Cox explains the reason behind Bazel’s name.
Jeff Cox explains the reason behind Bazel’s name.
Cox presented the roadmap for the tool and stated how the focus will be to evolve Bazel as a Platform. They want to improve Startlark rules API, revamp the external dependencies support to make it more usable for developers, and improve remote execution support. He also announced that starting from December, there will be Long Term Support releases with 9 months support window.
Migrating Twitter’s Monorepo from Pants to Bazel
Borja Lorente, Build Engineer at Twitter, explained how Twitter is migrating his monorepo from their in-house tool Pants to Bazel.
Twitter repo is a multilanguage 20 million lines of code plus a 10x generated code and over 2000 developers working on it. They wanted to minimize the friction for users during the migration, so big bang commits were not an option. As Lorente explained, migrating all at once would have been a pain both for users who had to learn how to use Bazel and for the build team that had to support the developers.
So they decided to do it gradually and maintain both Pants and Bazel at the same time. They did it by developing a Translation Layer. Bazel imports the Translation Layer at load time, uses it to translate Pants targets into Bazel rules, and returns the build graph containing Bazel targets.
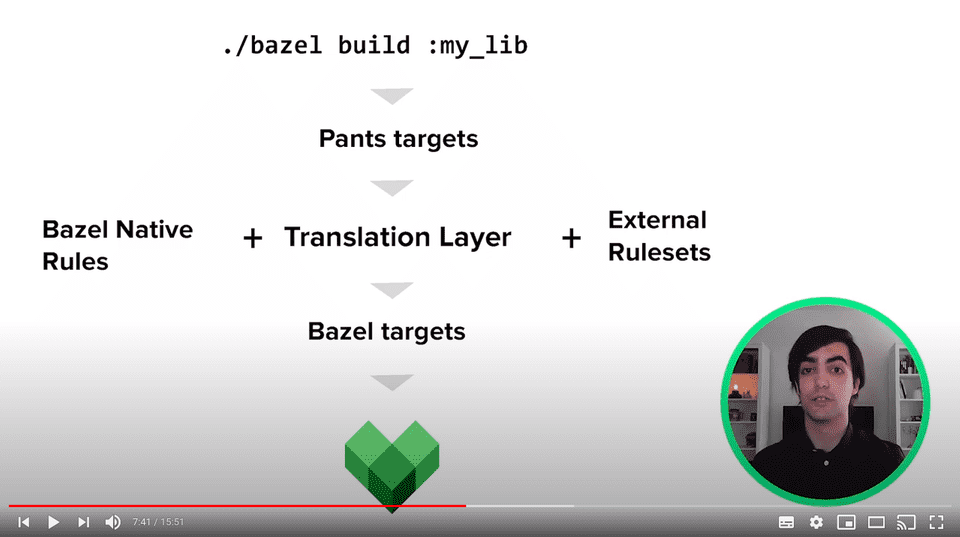 Borja Lorente explains the Translation Layer at Twitter.
Borja Lorente explains the Translation Layer at Twitter.
But it’s not so straightforward. There are differences between Pants and Bazel that the build team is tackling. Some of them involve dependencies.
In Pants targets have implicitly all their transitive dependencies when being compiled, rather in Bazel, you must explicitly export them. For 3rd party dependencies, Pants decide the version to use based on the build target, in Bazel, you need to explicitly define them before running.
Twitter journey to Bazel is still in progress and those and other issues are currently worked on by the build team.
Designing a Language Agnostic CI using Bazel Queries
Urvashi Reddy, Software Engineer at Pinterest from the Engineering Productivity Team presented a tool developed by her team to speed up their CI feedback cycle.
They realized that the CI was not able to detect which target changed so was it was frequently building all the targets.
This was too time-consuming.
They wanted to improve the situation by providing fast and reproducible builds and, at the same time, use a self-service approach: developers only need to write a BUILD file and not any new CI configuration. In this scenario, the BUILD file is the contract between developers and CI: developers dictate what want to run in CI within the BUILD file and the CI will take care of that.
 Urvashi Reddy explains how the CI stages work.
Urvashi Reddy explains how the CI stages work.
Reddy and her team developed a tool called build-collector that, given two commit SHAs, outputs the minimal set of modified targets.
The tool understands the kind of file changed and based on that runs a query to collect the affected targets. These targets are then used for the test stage and for the build and release stages. For the test stage, the tool runs an additional query to filter out only the test targets. For the build and release stages, they use another query but the strategy is different.
Reddy’s team has written a custom release macro used to publish release artifacts, called artifactscirelease. The macro makes the query easier since the build-collector can use it to collect the targets for the build and release stages.
Among the next steps, the team is planning to use an automatic process to identify flaky tests, tag them, and remove them from the running tests in CI. They also want to improve the query analysis performance using hashes.
Adopting Bazel in a Quickly Scaling Organization
Charles Essien, Engineering Lead at CarGurus, talked about how he and his team went from knowing next to nothing about Bazel to actively work with the Bazel community.
Pre Bazel the CarGurus’ monorepo had a lot of Dark Debt: it’s the measurable range on known unknowns or the things that you know you have to improve upon. The Dark Debt at CarGurus was in the form of a 1.2M lines of code monorepo where it was too easy to include packages and dependencies transitively in monolithic artifacts, slow build times, and a build that you couldn’t trust.
Essien explained how he and his team chose Bazel not only for the reproducible build but also to simplify: they managed to remove a lot of old code while adding only a few new to make Bazel work, decreasing the potential for tech debt. The team enabled developers to easily write new libraries and to safely reuse code thanks to BUILD visibility.
Talking about performance, after the bazelization, the build time went from 18 minutes with Maven in a developer laptop to 8 minutes with Bazel without a shared remote cache. With remote caching and remote execution, configured for a build without the bytes, the build time goes from 90 seconds to 5 and a half minutes in the worst case.
 Charles Essien explaining the results of the bazelization.
Charles Essien explaining the results of the bazelization.
The migration took 2 years and there were some huge challenges to face, one of the biggest was to clean up their java dependency graph and get rid of transitive dependencies, cyclic dependencies, and even duplicated dependencies. Essien had to work with developers in his organization to understand the intent behind dependencies and that slowed down the transition. He also mentioned that getting developers trust the tool and don’t clean the build was definitely not easy.
There were some takeaways from the migration. Observability is key since Essien and his team measured build times for Maven and Bazel and used it as a metric to show the practical benefits of Bazel. Another thing to focus on is the reproducibility of the build, meaning better caching for developers and less “it worked on my machine” as you scale
This is it!
You can find the whole Bazelcon 2020 here. Reach me on Twitter @gasparevitta and let me know what you learned at Bazelcon20!
- Next Article
Speed up Docker build time with cache warming - Previous Article
How to monitor a Docker image with Lazydocker